Nils Heuman
Custom Firefox AI Sidebar
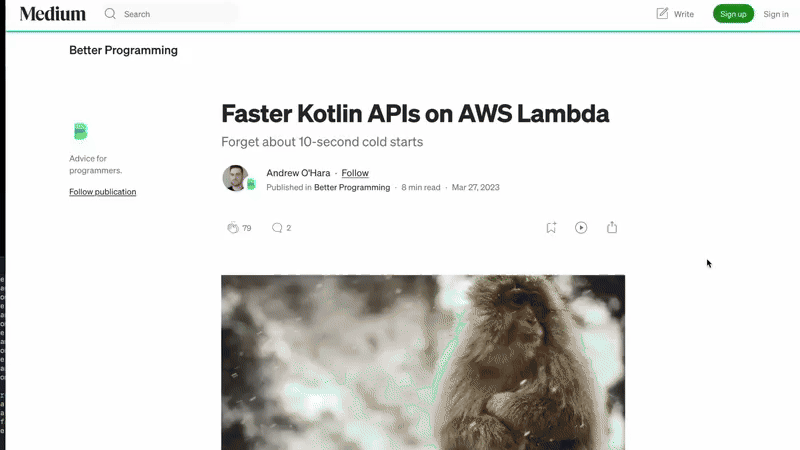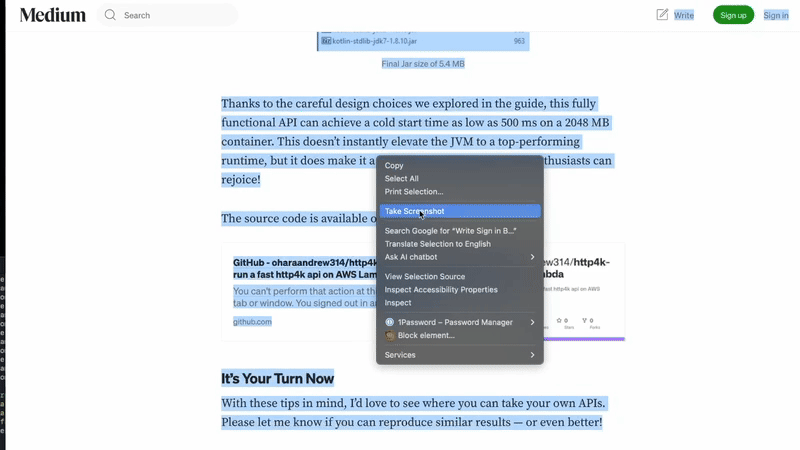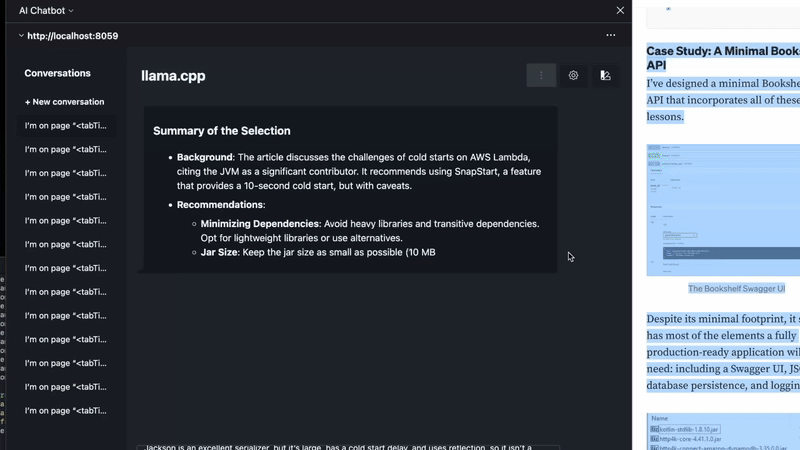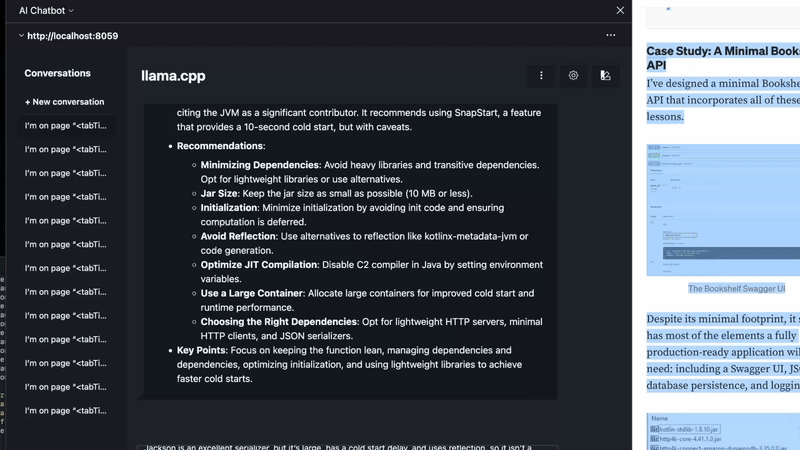
Firefox has a AI sidebar that can be shown with ctrl+x (mac) ctrl+alt+x (windows?).
Once activated it appears as ‘Ask AI Chatbot’ in the right click menu.
Currently it seems to be fairly simple, you can select text on a web page (limited length) and select a prompt to send to your AI provider.
Basically what it does is to send a http request to /?q=<prompt>.
Different providers can be selected, localhost is not shown by default.
So a few changes needs to be done to get that to work.
Enable localhost and Customize prompts
Firefox AI sidebar can be customized by editing settings in about:config.
Enter it in the url field and then search for browser.ml.chat to find the settings.
To use a local server (llama.cpp server works great) a few settings can be changed as below:
Set hideLocalhost to false to give the option to choose localhost when selecting a provider.
browser.ml.chat.hideLocalhost = false
Set the provider to your local server, default is 8080 but can be changed.
browser.ml.chat.provider = http://localhost:8080
The buttons in the right click menu can be edited with the format below for custom prompts:
browser.ml.chat.prompts.4 = {
"id": "custom",
"label": "Custom Action",
"value":"custom prompt"
}
Sample prompts
Translate with local model
{"id":"custom-translate","label":"Translate","value":"Please translate the selection using precise and concise language. Maintain the meaning and factual accuracy. Do not include the text before the `<selection>` tag in the translation or your response. Only respond with the translation and nothing else. Use markdown syntax where it seems suitable but do not add bullet lists unless the selected text explicity contains them."}
Short TLDR, not as stable as the original summarize but shorter
{"id":"tldr","label":"TLDR","value":"Please summarize the selection using precise and concise language, keep it short like a TLDR. Use headers and bulleted lists in the summary, to make it scannable. Maintain the meaning and factual accuracy."}
Using Firefox AI Sidebar with a custom llama.cpp frontend
A few minor changes is nice to do to the web ui in llama.cpp/examples/server/webui
- Hide the first message (the question from the browser)
- Uncheck the default showing of sidebar. (to avoid it expanding on every query)
- Put a custom url if running the llama.cpp frontend from vite to point to the real llama.cpp server
Since the changes are so small and the project is moving so fast I’ve just listen the little hacks below:
So first clone the repo from https://github.com/ggml-org/llama.cpp
examples/server/webui/src/Config.ts
- export const BASE_URL = new URL('.', document.baseURI).href
+ export const BASE_URL = new URL('.', "http://localhost:8055").href
examples/server/webui/src/components/ChatScreen.tsx
- {[...messages, ...pendingMsgDisplay].map((msg) => (
+ {[...(messages.slice(1)), ...pendingMsgDisplay].map((msg) => (
examples/server/webui/src/components/Sidebar.tsx
- defaultChecked
+ // defaultChecked
examples/server/webui/vite.config.ts
server: {
+ port: 8059,
Running the custom llama.cpp frontend
To run in dev mode:
cd examples/server/webui
npm install
npm run dev
Running llama.cpp
Install (on mac with homebrew, see official instructions for other methods)
brew install llama.cpp
Running the server with a small model
llama-server -hf Qwen/Qwen2.5-1.5B-Instruct-GGUF
Once the model is downloaded, you can run llama.cpp with the following command to avoid connecting to huggingface.co, this also listen to all interfaces and port 8052
llama-server \
-m $HOME/Library/Caches/llama.cpp/Qwen_Qwen2.5-1.5B-Instruct-GGUF_qwen2.5-1.5b-instruct-q4_k_m.gguf \
--host 0.0.0.0 --port 8052